 Products Home
Products HomeUnmounted Dove Prisms

- Rotate, Invert, or Retroreflect an Image
- Six Different Sizes Available
- Available Uncoated or AR Coated for 350 - 700 nm or 650 - 1050 nm
PS990
PS991
PS992-A
PS993
Application Idea
KM200B Kinematic Platform Mount Provides
Tip and Tilt Control of PS992 Dove Prism









Please Wait
| Common Specificationsa | |
|---|---|
| Material | N-BK7b |
| Clear Aperture | >70% of Max Face Length and Width |
| Surface Quality of Polished Surfaces | 40-20 Scratch-Dig |
| Surface Flatness | λ/5 at 632.8 nm |


Features
- Rotate and Invert an Image or Retroreflect Light
- Offered Uncoated in Six Face Widths: 5 mm, 10 mm, 15 mm, 20 mm, 25 mm, and 30 mm
- 15 mm Size Also Available with One of Two AR Coatings
- 350 - 700 nm
- 650 - 1050 nm
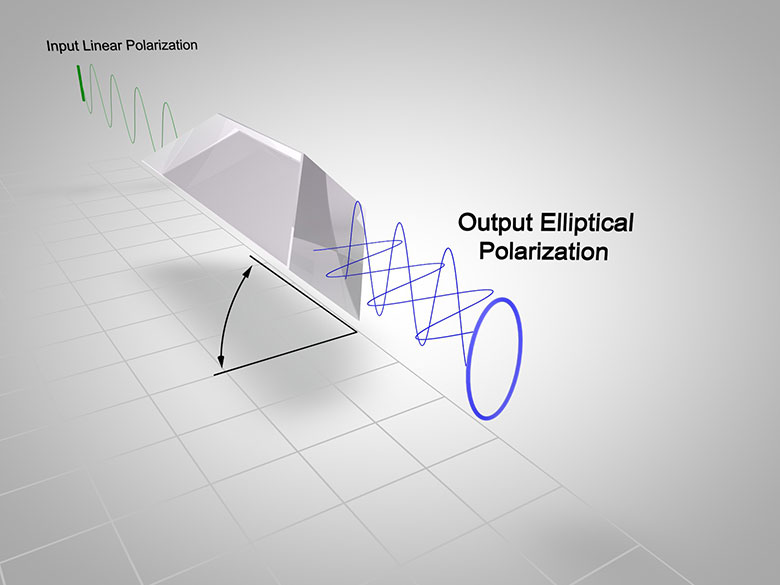
A Dove prism is used to rotate, invert, or retroreflect an image, depending upon the prism's rotation angle and the surface through which the light enters the prism. Thorlabs' Dove Prisms are fabricated from N-BK7 glass for high transmission from the visible to the near-infrared spectral range and available uncoated with 5 mm, 10 mm, 15 mm, 20 mm, 25 mm, or 30 mm square cross sections (see the Specs tab for more information on dimensions). Our 15 mm version is available uncoated or with one of two AR coatings deposited on the two angled faces. We also offer Dove prisms mounted in SM-threaded housings. For information on our full selection of prisms, please see the Prism Guide tab.
Dove prisms can be thought of as right-angle prisms with the triangular apex removed, which reduces the weight of the prism and stray internal reflections. They introduce astigmatism when used with converging light, so we recommend using them with collimated light. Additionally, these prisms affect the polarization state of light transmitted through them. See the Lab Facts tab for further details.
Shown at the top of the page is a Dove prism mounted in a retroreflection geometry, as described under Retroreflection below. In this photo, the Dove prism is secured to a KM200B Kinematic Platform Mount by a PM4 Clamping Arm. For applications sensitive to the polarization of the transmitted light, care should be taken when clamping these prisms. Stress-induced birefringence further alters the polarization of light incident on the prism. See the Lab Facts tab for more information.
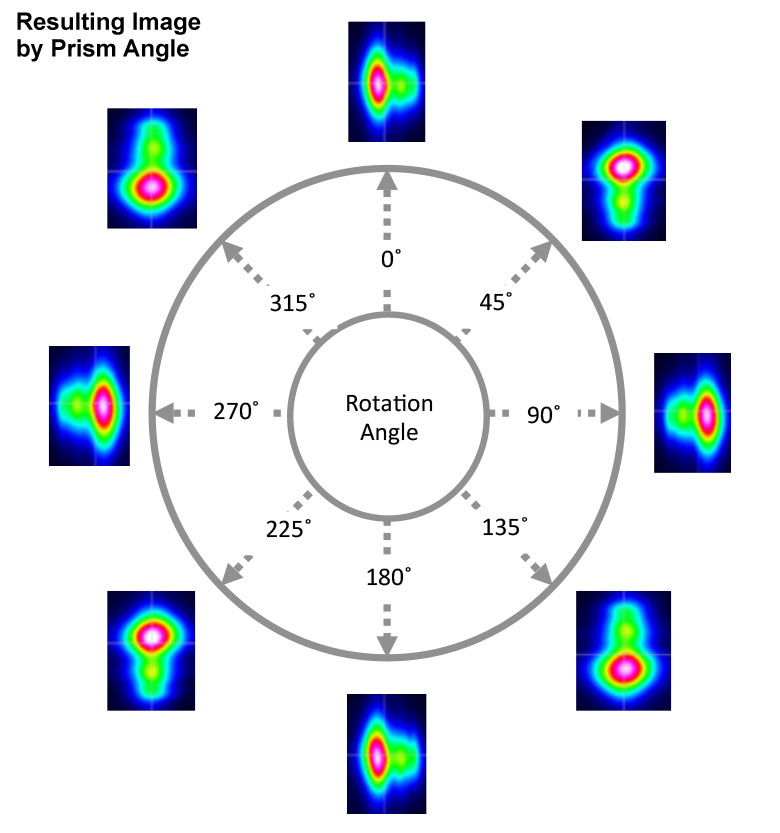
This animation shows how the image rotates as the prism is rotated.
Image Rotation
Light is usually propagated along the longitudinal axis of a Dove prism. In this geometry, shown in the diagrams on the bottom left and middle, light reflects once from the bottom face, inverting the image on the other side. Rotation of the prism about the longitudinal axis rotates the image at twice the rate of the prism's rotation (see video to the right). For example, a 20° rotation of the prism results in a 40° rotated image. The AR-coated Dove prisms are designed specifically for the image rotation and inversion application.
Due to the high incidence angle, the light reflecting from the bottom face undergoes total internal reflection, even if the light's propagation axis and the prism's longitudinal axis are not exactly parallel. Hence, in a Dove prism, the magnitude of the internal transmission is limited only by absorption.
Retroreflection
When light is incident on the longest face, the Dove prism acts as a retroreflector or a right-angle prism. The light exits parallel to the input light (independent of the incidence angle) and is inverted by 180°. This geometry is shown below and to the right. In situations with limited space or where more convenient mounting options are needed, the Dove prism can replace a retroreflector or right-angle prism.
Custom Coatings
Upon request, our prisms can be AR coated for the 290 - 370 nm (-UV), 350 - 700 nm (-A), 650 - 1050 nm (-B), or 1050 - 1700 (-C) spectral ranges. Please contact Technical Support for more information.
 Zemax Files Zemax Files |
|---|
| Click on the red Document icon next to the item numbers below to access the Zemax file download. Our entire Zemax Catalog is also available. |

Light propagated along the longitudinal axis is inverted by 180°.
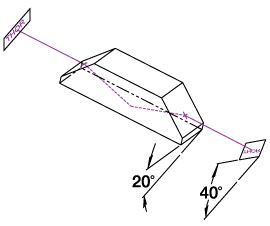
Rotation of the prism over some angle results in a rotation of the image over twice that angle.
Light incident on the longest face of the prism is retroreflected and inverted by 180°.
| Dimensions of Unmounted Prismsa | |||
|---|---|---|---|
| Item # Prefix | A | B | Lb |
| PS990 | 5 mm | 7.1 mm | 21.1 mm |
| PS991 | 10 mm | 14.1 mm | 42.2 mm |
| PS992 | 15 mm | 21.2 mm | 63.4 mm |
| PS994 | 20 mm | 28.3 mm | 84.5 mm |
| PS995 | 25 mm | 35.4 mm | 105.7 mm |
| PS993 | 30 mm | 42.4 mm | 126.3 mm |
| General Specifications | |
|---|---|
| Material | N-BK7a |
| Clear Aperture | >70% of Max Face Length and Widthb |
| Surface Quality of Polished Surfaces | 40-20 Scratch-Dig |
| Surface Flatness | λ/5 at 632.8 nm |
| Optically Polished Surfacesb | S1, S2, and S3 |
| Fine Ground Surfacesb | All Surfaces Except S1, S2, and S3 |
| Dimensional Tolerance | ±0.15 mm |
| Angular Tolerance | ±3 arcmin |
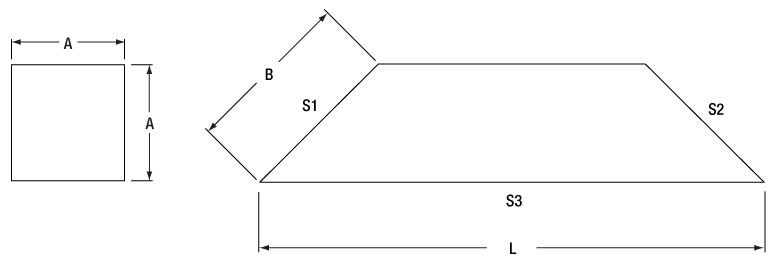
Click to Enlarge
Cross-Sectional View (Left) and Side View (Right) of a Dove Prism
| AR Coating Specifications | ||
|---|---|---|
| Item # | PS992-A | PS992-B |
| Wavelength Range | 350 - 700 nm | 650 - 1050 nm |
| Reflectance Over AR Coating Range (Avg., AOI = 45° with Respect to the Coated Surface) |
<1% | |
| AR-Coated Surfacesa | S1 and S2 | |
The transmission curve for N-BK7, a RoHS-compliant form of BK7, is shown below. The data was obtained for a 10 mm thick, uncoated sample and includes surface reflections. For an excel file of the data, please click the link below the graph.
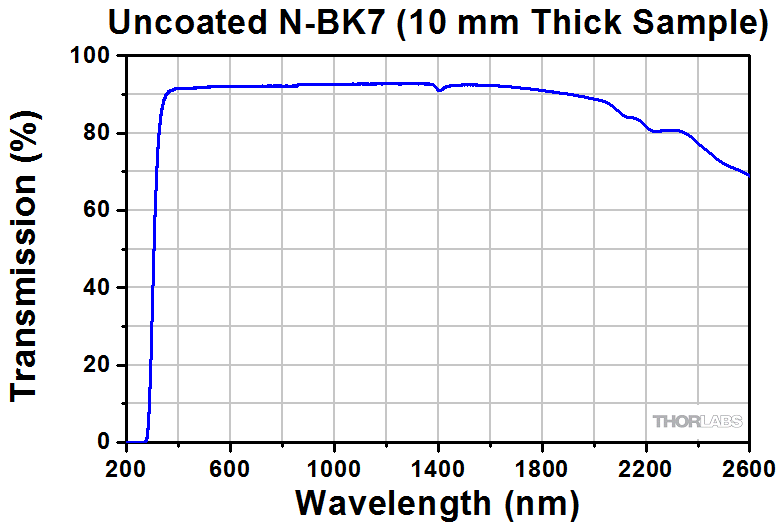
Click to Enlarge
Click Here for Raw Data
The graphs below give the measured reflectance of AR-coated Dove prisms at a 45° AOI with respect to the coated surface. The graph on the left corresponds to the PS992-A Dove prism, while the graph on the right corresponds to the PS992-B Dove prism. For Excel files of the reflectance data, please click the links below the graphs.
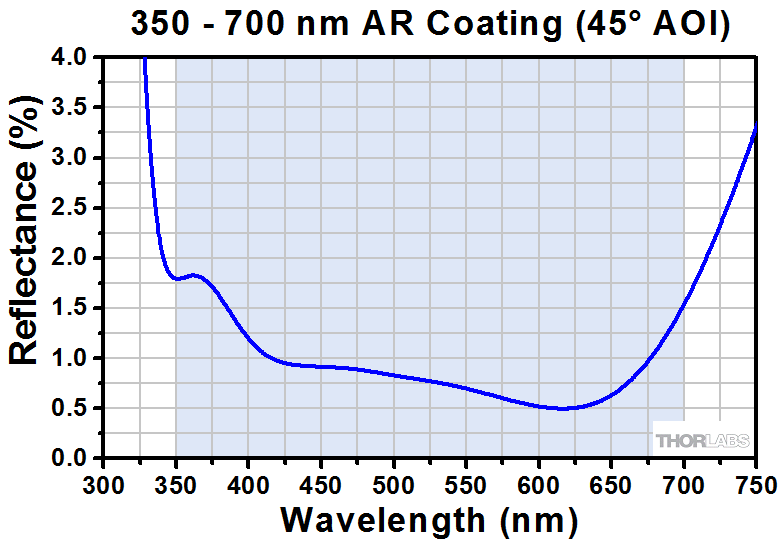
Click to Enlarge
Click Here for Raw Data
Please note that this is measured reflectance data. The shaded region indicates the range over which we guarantee the average reflectance will be <1% for a 45° AOI.
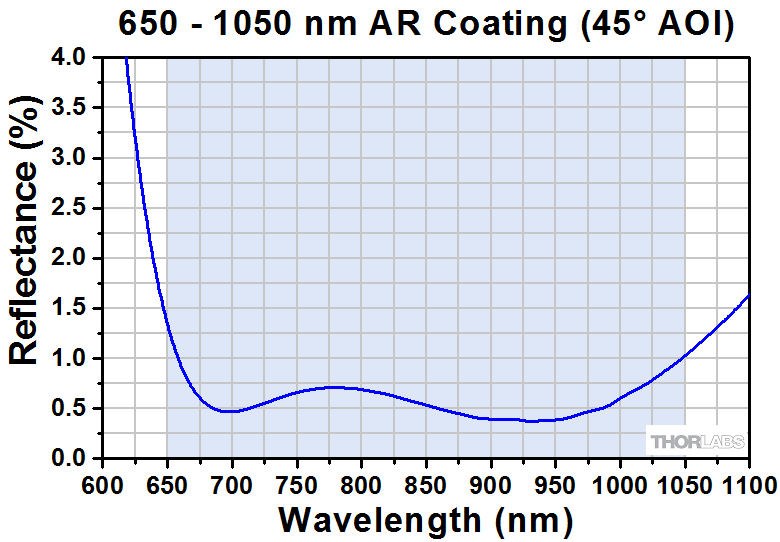
Click to Enlarge
Click Here for Raw Data
Please note that this is measured reflectance data. The shaded region indicates the range over which we guarantee the average reflectance will be <1% for a 45° AOI.
Thorlabs Lab Fact: Dove Prisms Alter Polarization State and Image Orientation
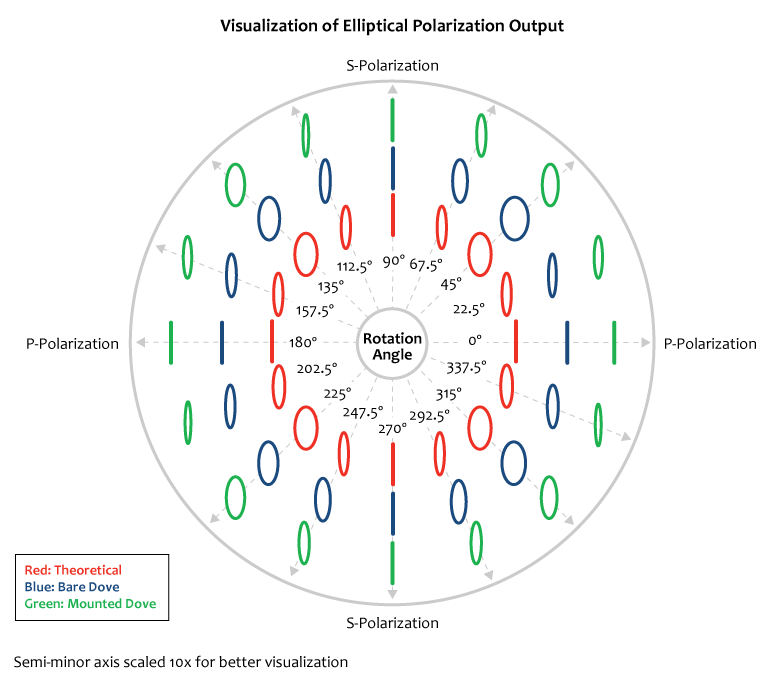
We present laboratory measurements of the polarization and rotation state of a beam transmitted through Thorlabs’ PS992 and PS992M Dove Prisms. We also examine the influence of stress-induced birefringence on the final polarization state. In a polarization-dependent experiment, it is important to understand how the polarization and orientation of the input beam is altered by a Dove prism. While it is known that Dove prisms introduce changes in the polarization of the transmitted light [1], we also find that localized stress-induced birefringence can significantly alter the polarization state. Finally we compare theoretical predictions of induced polarization change to the measured polarization change for both our unmounted and mounted versions of Dove prism.
For our experiment we used the HL6320G Laser Diode (635 nm) as the light source. The laser beam was initially aligned using two crossed Glan-Taylor polarizers (GT10-A). The first polarizer set the polarization axis, and the rotation angle of the second crossed polarizer was recorded. The Dove prism was then placed in between the two polarizers, and the power of the beam was recorded after the second polarizer as a function of prism angle. Additionally, measurements were taken to determine the radii and orientation angle of the polarization ellipse. The polarization shift caused by the PS992 unmounted Dove prism and PS992M mounted Dove prism were measured. The unmounted prism was tested for polarization changes due to birefringence effects as well.

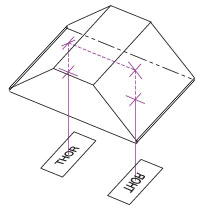
The figure to the top right summarizes the measured results for image orientation as a function of prism angle. While it is well known that Dove prisms are used to invert images, it is interesting to note that the image rotation angle is twice that of the prism rotation angle. The figure to the bottom left summarizes the results of stress-induced birefringence on polarization state, while the figure to the bottom right summarizes the effects a Dove prism has on the polarization state and compares that to the theoretical values. Data is presented for both the unmounted and mounted Dove prisms with minimal stress. While Dove prisms do rotate the image, the polarization does not rotate with the image. Rather, the polarization is transformed from linear to various degrees of elliptical. For details on the experimental setup employed and the results summarized here, please click here.

[1] Miles J. Padgett & J. Paul Lesso, "Dove prisms and polarized light," J. Mod. Opt. 46, 175-179 (1999).
Selection Guide for Prisms
Thorlabs offers a wide variety of prisms, which can be used to reflect, invert, rotate, disperse, steer, and collimate light. For prisms and substrates not listed below, please contact Tech Support.
Beam Steering Prisms
| Prism | Material | Deviation | Invert | Reverse or Rotate | Illustration | Applications |
|---|---|---|---|---|---|---|
| Right Angle Prisms | N-BK7, UV Fused Silica, Calcium Fluoride, or Zinc Selenide | 90° | 90° | No |  |
90° reflector used in optical systems such as telescopes and periscopes. |
| 180° | 180° | No |  |
180° reflector, independent of entrance beam angle. Acts as a non-reversing mirror and can be used in binocular configurations. |
||
| TIR Retroreflectors (Unmounted and Mounted) and Specular Retroreflectors (Unmounted and Mounted) |
N-BK7 | 180° | 180° | No | 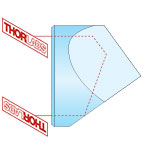 |
180° reflector, independent of entrance beam angle. Beam alignment and beam delivery. Substitute for mirror in applications where orientation is difficult to control. |
| Unmounted Penta Prisms and Mounted Penta Prisms |
N-BK7 | 90° | No | No | 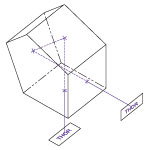 |
90° reflector, without inversion or reversal of the beam profile. Can be used for alignment and optical tooling. |
| Roof Prisms | N-BK7 | 90° | 90° | 180o Rotation | 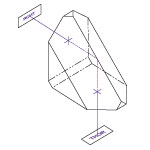 |
90° reflector, inverted and rotated (deflected left to right and top to bottom). Can be used for alignment and optical tooling. |
| Unmounted Dove Prisms and Mounted Dove Prisms |
N-BK7 | No | 180° | 2x Prism Rotation | 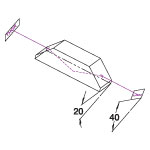 |
Dove prisms may invert, reverse, or rotate an image based on which face the light is incident on. Prism in a beam rotator orientation. |
| 180° | 180° | No |  |
Prism acts as a non-reversing mirror. Same properties as a retroreflector or right angle (180° orientation) prism in an optical setup. |
||
| Wedge Prisms | N-BK7 | Models Available from 2° to 10° | No | No | 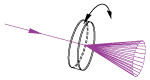 |
Beam steering applications. By rotating one wedged prism, light can be steered to trace the circle defined by 2 times the specified deviation angle. |
| No | No | 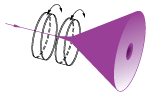 |
Variable beam steering applications. When both wedges are rotated, the beam can be moved anywhere within the circle defined by 4 times the specified deviation angle. |
|||
| Coupling Prisms | Rutile (TiO2) or GGG | Variablea | No | No | 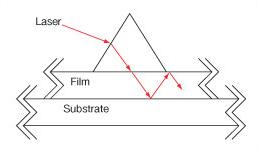 |
High index of refraction substrate used to couple light into films. Rutile used for nfilm > 1.8 GGG used for nfilm < 1.8 |
Dispersive Prisms
| Prism | Material | Deviation | Invert | Reverse or Rotate | Illustration | Applications |
|---|---|---|---|---|---|---|
| Equilateral Prisms | F2, N-F2, N-SF11, Calcium Fluoride, or Zinc Selenide |
Variablea | No | No | 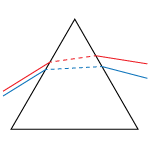 |
Dispersion prisms are a substitute for diffraction gratings. Use to separate white light into visible spectrum. |
| Dispersion Compensating Prism Pairs | Fused Silica, Calcium Fluoride, SF10, or N-SF14 | Variable Vertical Offset | No | No | 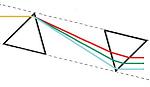 |
Compensate for pulse broadening effects in ultrafast laser systems. Can be used as an optical filter, for wavelength tuning, or dispersion compensation.
|
| Pellin Broca Prisms | N-BK7, UV Fused Silica, or Calcium Fluoride |
90° | 90° | No | 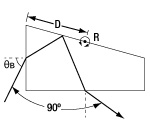 |
Ideal for wavelength separation of a beam of light, output at 90°. Used to separate harmonics of a laser or compensate for group velocity dispersion. |
Beam Manipulating Prisms
| Prism | Material | Deviation | Invert | Reverse or Rotate | Illustration | Applications |
|---|---|---|---|---|---|---|
| Anamorphic Prism Pairs | N-KZFS8 or N-SF11 |
Variable Vertical Offset | No | No |  |
Variable magnification along one axis. Collimating elliptical beams (e.g., laser diodes) Converts an elliptical beam into a circular beam by magnifying or contracting the input beam in one axis. |
| Axicons (UVFS, ZnSe) | UV Fused Silica or Zinc Selenide |
Variablea | No | No | 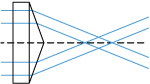 |
Creates a conical, non-diverging beam with a Bessel intensity profile from a collimated source. |
Polarization Altering Prisms
| Prism | Material | Deviation | Invert | Reverse or Rotate | Illustration | Applications |
|---|---|---|---|---|---|---|
| Glan-Taylor, Glan-Laser, and α-BBO Glan-Laser Polarizers | Glan-Taylor: Calcite Glan-Laser: α-BBO or Calcite |
p-pol. - 0° s-pol. - 112°a |
No | No | 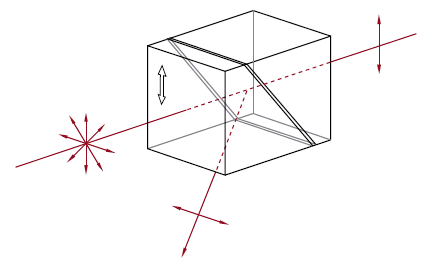 |
Double prism configuration and birefringent calcite produce extremely pure linearly polarized light. Total Internal Reflection of s-pol. at the gap between the prism while p-pol. is transmitted. |
| Rutile Polarizers | Rutile (TiO2) | s-pol. - 0° p-pol. absorbed by housing |
No | No | 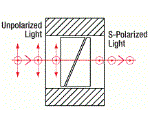 |
Double prism configuration and birefringent rutile (TiO2) produce extremely pure linearly polarized light. Total Internal Reflection of p-pol. at the gap between the prisms while s-pol. is transmitted.
|
| Double Glan-Taylor Polarizers | Calcite | p-pol. - 0° s-pol. absorbed by housing |
No | No | 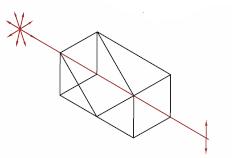 |
Triple prism configuration and birefringent calcite produce maximum polarized field over a large half angle. Total Internal Reflection of s-pol. at the gap between the prism while p-pol. is transmitted. |
| Glan Thompson Polarizers | Calcite | p-pol. - 0° s-pol. absorbed by housing |
No | No |  |
Double prism configuration and birefringent calcite produce a polarizer with the widest field of view while maintaining a high extinction ratio. Total Internal Reflection of s-pol. at the gap between the prism while p-pol. is transmitted. |
| Wollaston Prisms and Wollaston Polarizers |
Quartz, Magnesium Fluoride, α-BBO, Calcite, Yttrium Orthovanadate | Symmetric p-pol. and s-pol. deviation angle |
No | No | 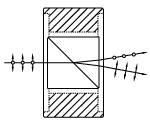 |
Double prism configuration and birefringent calcite produce the widest deviation angle of beam displacing polarizers. s-pol. and p-pol. deviate symmetrically from the prism. Wollaston prisms are used in spectrometers and polarization analyzers. |
| Rochon Prisms | Magnesium Fluoride or Yttrium Orthovanadate |
Ordinary Ray: 0° Extraordinary Ray: deviation angle |
No | No |  |
Double prism configuration and birefringent MgF2 or YVO4 produce a small deviation angle with a high extinction ratio. Extraordinary ray deviates from the input beam's optical axis, while ordinary ray does not deviate. |
| Beam Displacing Prisms | Calcite | 2.7 or 4.0 mm Beam Displacement | No | No | 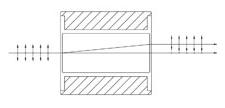 |
Single prism configuration and birefringent calcite separate an input beam into two orthogonally polarized output beams. s-pol. and p-pol. are displaced by 2.7 or 4.0 mm. Beam displacing prisms can be used as polarizing beamsplitters where 90o separation is not possible. |
| Fresnel Rhomb Retarders | N-BK7 | Linear to circular polarization Vertical Offset |
No | No | 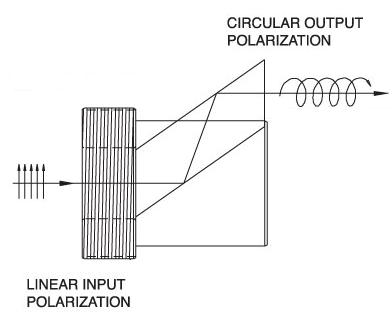 |
λ/4 Fresnel Rhomb Retarder turns a linear input into circularly polarized output. Uniform λ/4 retardance over a wider wavelength range compared to birefringent wave plates. |
| Rotates linearly polarized light 90° | No | No |  |
λ/2 Fresnel Rhomb Retarder rotates linearly polarized light 90°. Uniform λ/2 retardance over a wider wavelength range compared to birefringent wave plates. |
Beamsplitter Prisms
| Prism | Material | Deviation | Invert | Reverse or Rotate | Illustration | Applications |
|---|---|---|---|---|---|---|
| Beamsplitter Cubes | N-BK7 | 50:50 splitting ratio, 0° and 90° s- and p- pol. within 10% of each other |
No | No | 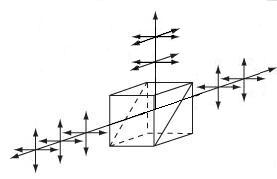 |
Double prism configuration and dielectric coating provide 50:50 beamsplitting nearly independent of polarization. Non-polarizing beamsplitter over the specified wavelength range. |
| Polarizing Beamsplitter Cubes | N-BK7, UV Fused Silica, or N-SF1 | p-pol. - 0° s-pol. - 90° |
No | No | 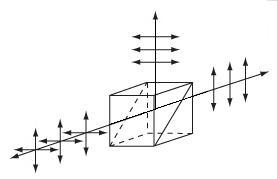 |
Double prism configuration and dielectric coating transmit p-pol. light and reflect s-pol. light. For highest polarization use the transmitted beam. |
| Posted Comments: | |
phycfc
(posted 2017-08-23 12:50:21.463) Do you sell dove prism with all sides of the prism polished? tfrisch
(posted 2017-09-14 03:50:36.0) Hello, thank you for contacting Thorlabs. I will reach out to you about details for this quote. cplechaty
(posted 2014-09-09 08:22:42.36) Do you sell a mount for these such that I can rotate it along its long axis (similar to the mounted version)? I require a larger aperture than the mounted Dovetail prism provides. Thanks. jlow
(posted 2014-09-18 10:49:11.0) Response from Jeremy at Thorlabs: We can provide a modified version of our mount with larger aperture. I will contact you directly about this. apalmentieri
(posted 2010-03-16 15:58:05.0) A response from Adam at Thorlabs to j.m.smit: The Field of View is around +/- 3.4 degrees in the y direction (up/down), and +3.4/-0.3 in the x direction (left/right) when the eye is placed on the optical axis at 30mm away from the slant surface. j.m.smit
(posted 2010-03-15 16:10:11.0) Hi,
Could you please give an indication of the Field of View for the DOVE prims PS992 when the eye is placed on the optical axis at 30mm away from the slant surface ?
Thanks a lot,
Dr. J.M.Smit
SRON Netherlands Inst. for Space Research.
j.m.smit@sron.nl |

 Zoom
Zoom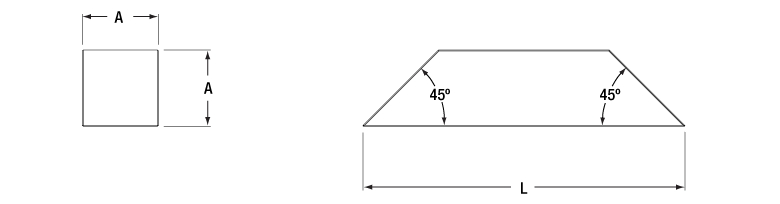
Click to Enlarge
Cross-Sectional View (Left) and Side View (Right) of a Dove Prism
| Item # | Aa | La |
|---|---|---|
| PS990 | 5 mm | 21.1 mm |
| PS991 | 10 mm | 42.2 mm |
| PS992 | 15 mm | 63.4 mm |
| PS994 | 20 mm | 84.5 mm |
| PS995 | 25 mm | 105.7 mm |
| PS993 | 30 mm | 126.3 mm |
- Uncoated N-BK7 for the 350 nm to 2.0 µm Wavelength Range
- Available in Six Sizes (See Table and Diagram to the Right)
- Rotate, Invert, or Retroreflect an Image
These unmounted, uncoated Dove prisms are offered with six different square cross sections (see table and diagram to the right). As described in the Overview tab above, the two angled faces are typically used together to rotate an image, while the longest face can be used to retroreflect an image. The angled faces and longest face of our Dove prisms are optically polished surfaces. All other surfaces are fine ground to permit handling of the prism.

 Zoom
Zoom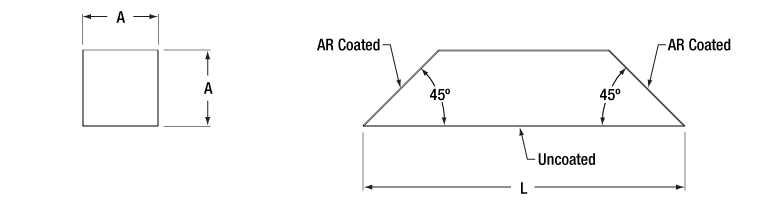
Click to Enlarge
Cross-Sectional View (Left) and Side View (Right) of a Dove Prism
- AR Coated for the 350 nm to 700 nm Wavelength Range
- Available in One Size: A = 15 mm, L = 63.4 mm (See Diagram to the Right)
- Rotate or Invert an Image
This Dove prism has a 15 mm square cross section and an AR coating for 350 to 700 nm deposited on the two angled faces (shown in the diagram to the right). This coating provides an average reflectance of <1% over the specified wavelength range. For a plot of the reflectance versus wavelength, please see the Graphs tab.
As described in the Overview tab above, the two angled faces of a Dove prism are typically used together to rotate an image. With an AR coating on both angled faces, this prism is specifically designed for image inversion and rotation. The angled faces and longest face of this Dove prism are optically polished surfaces. All other surfaces are fine ground to permit handling of the prism.

 Zoom
Zoom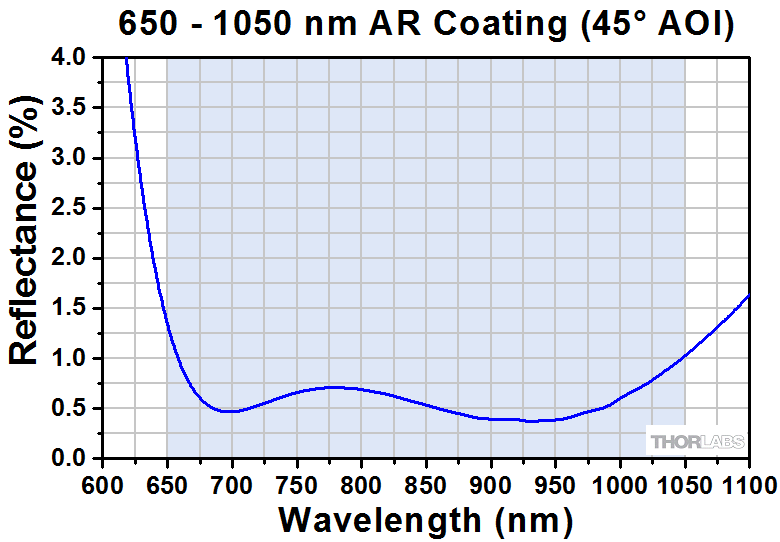{kind=link}
Click to Enlarge
Cross-Sectional View (Left) and Side View (Right) of a Dove Prism
- AR Coated for the 650 nm to 1050 nm Wavelength Range
- Available in One Size: A = 15 mm, L = 63.4 mm (See Diagram to the Right)
- Rotate or Invert an Image
This Dove prism has a 15 mm square cross section and an AR coating for 650 to 1050 nm deposited on the two angled faces (shown in the diagram to the right). This coating provides an average reflectance of <1% over the specified wavelength range. For a plot of the reflectance versus wavelength, please see the Graphs tab.
As described in the Overview tab above, the two angled faces of a Dove prism are typically used together to rotate an image. With an AR coating on both angled faces, this prism is specifically designed for image inversion and rotation. Please note that the AR coating makes these prisms unsuitable for use as retroreflectors. For retroreflecting applications, please use our uncoated Dove prisms. The angled faces and longest face of this Dove prism are optically polished surfaces. All other surfaces are fine ground to permit handling of the prism.